
みなさん、こんにちは。
今回はこれまで自前で構築したオンプレ環境やPC上で動かしていた機械学習の処理をAWS Batchで動かすまでの第2回です。
1. コンテナ作成用実行環境準備(cloud9+docker+GPU環境)
2. 文字起こし用のdockerfileとdocker-compose.ymlの設定とcloud9上でのコンテナ内でのプログラム実行
3. コンテナをdocker pushでAWSで使える状態にする
4. AWS Batchの設定とジョブ実行してみる
5. StepFunctionを使ってS3と連携してみる
今回の内容は「2. 文字起こし用のdockerfileとdocker-compose.ymlの設定とcloud9上でのコンテナ内でのプログラム実行」です。
以下のファイルを準備してcloud9内で文字起こしを実行するところまで実施していきます。
■ファイルの設定変更と追加
・まずはDockerfileの設定を以下のように変更します。
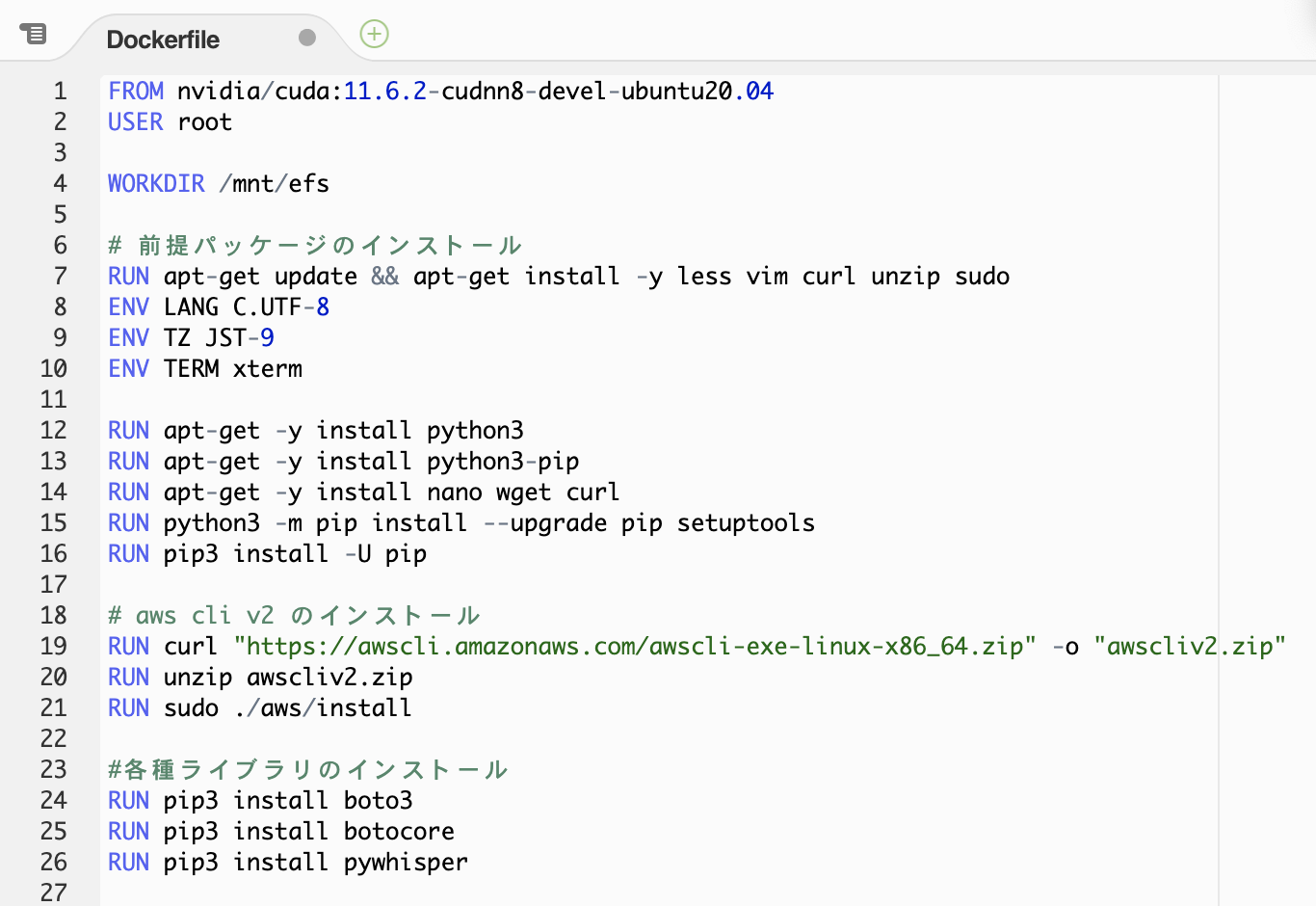
・次にdocker-compose.ymlの設定を変更します。
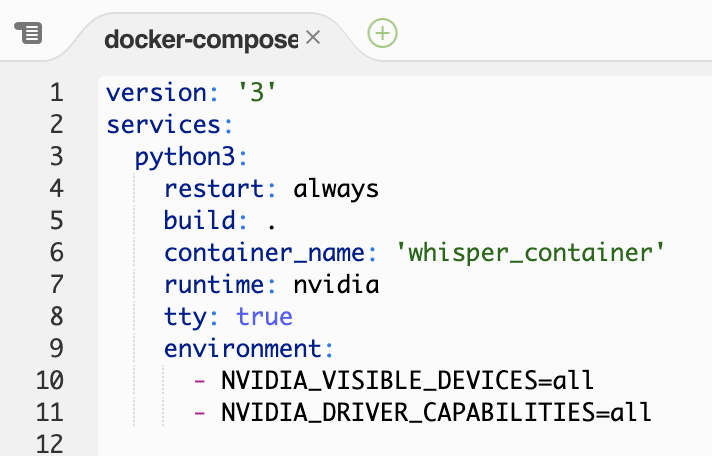
・文字起こしを実行するためのwhisper_test.pyを追加します。
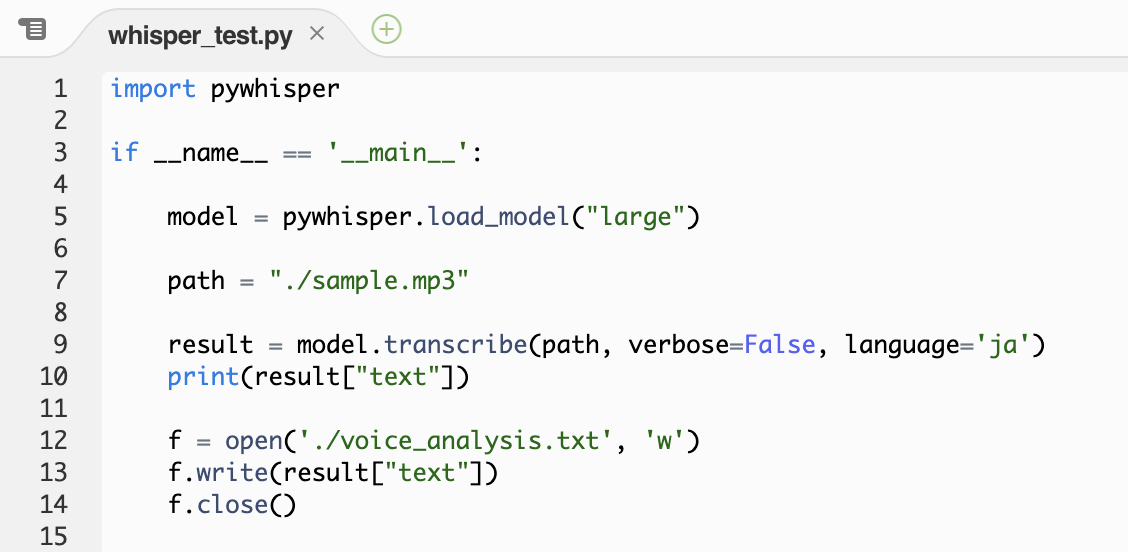
・文字起こしをする音声ファイルsampel.mp3を配置(wav形式でもOK)
ファイルの変更と追加は以上です。
次からはDcokerのコンテナ作成をします。
■Dockerコンテナ環境再構築と文字起こしの実行
・まずは、Dockerの再ビルドをします。
$ docker-compose up -d --build・起動しているdockerプロセス確認します。
$ docker ps・再ビルドしたコンテナ内に入ります。
$ docker exec -it whisper_container bash・python実行(しばらく待つと文字起こしが始まります)
# python3 whisper_test.py
(※出力されたテキストは内容が分からないようにボカシをいれています)
・以下のコマンドでもファイルに保存した文字起こしの結果を確認できます。
#vi voice_analysis.txt■まとめ
今回はdockerコンテナ内に入って実行しました。
最終ゴールはS3に音声ファイルがアップロードされたら自動実行することです。
次回はAWS Batchにdocker pushを実行していきます。
今回は以上です。
最後までありがとうございました。
また第3回(#3)でお会いしましょう。